
Standing in 2018, models with image classification accuracy above 95% have been everywhere.
Recall that in 2012, Hinton shocked the computer vision research community with students with an error rate of 16.4% on ImageNet, which seems to be a history of ancient times.
Is it really credible to make rapid progress over the years?
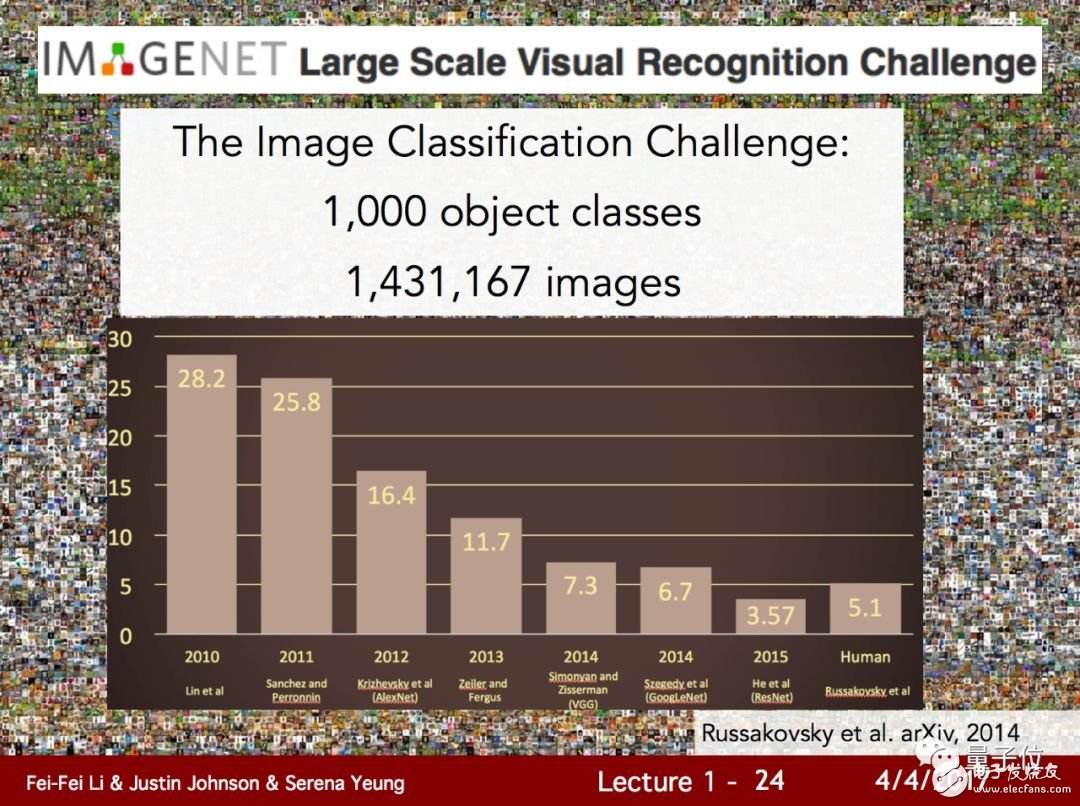
A recent study led to some reflection: these advances are suspicious.
The study, a paper published by UC Berkeley and several MIT scientists at arXiv: Do CIFAR-10 Classifiers Generalize to CIFAR-10?.
Explain that this seemingly weird question – “Can the CIFAR-10 classifier be generalized to CIFAR-10?†is a big flaw in today's deep learning research:
A deep learning model that seems to have a good grade is not useful in the real world. Because many of the good results of models and training methods come from over-fitting for those well-known benchmark validation sets.
The paper points out that in the past five years, most published papers have embraced a paradigm: a new machine learning method that determines the status of data in several key benchmarks.
However, compared with the predecessors, why is there such an improvement? Very few people explained it. Our perception of progress is based primarily on several standard benchmarks such as CIFAR-10, ImageNet, and MuJoCo.
This brings up a key question: How reliable is our current measure of machine learning progress?
This allegation almost doubts all the advances in image classification algorithms over the years.
Nothing to say, how to prove?
To illustrate this problem, several authors took out 30 image classification models that performed well on the CIFAR-10 validation set, tested them with a data set, and spoke with the results.
CIFAR-10 contains 60,000 32&TImes; 32-pixel color images, divided into 5 training batches (batch) and 1 test batch image. There are 10 categories: airplane, car, bird, cat, deer, dog, frog. , boats, trucks.

Of course, if you just find a data set to test, there is a suspicion of bullying AI. For this purpose, they created a test set very similar to CIFAR-10, containing 2000 new images, the same image source, the same data sub-category distribution, and even the division of labor during the construction process.
This new data set, the second CIFAR-10 mentioned in the title of the paper, should be exactly the "small test set of high imitation CIFAR-10".
The new test set brought a significant blow to the model, as follows:
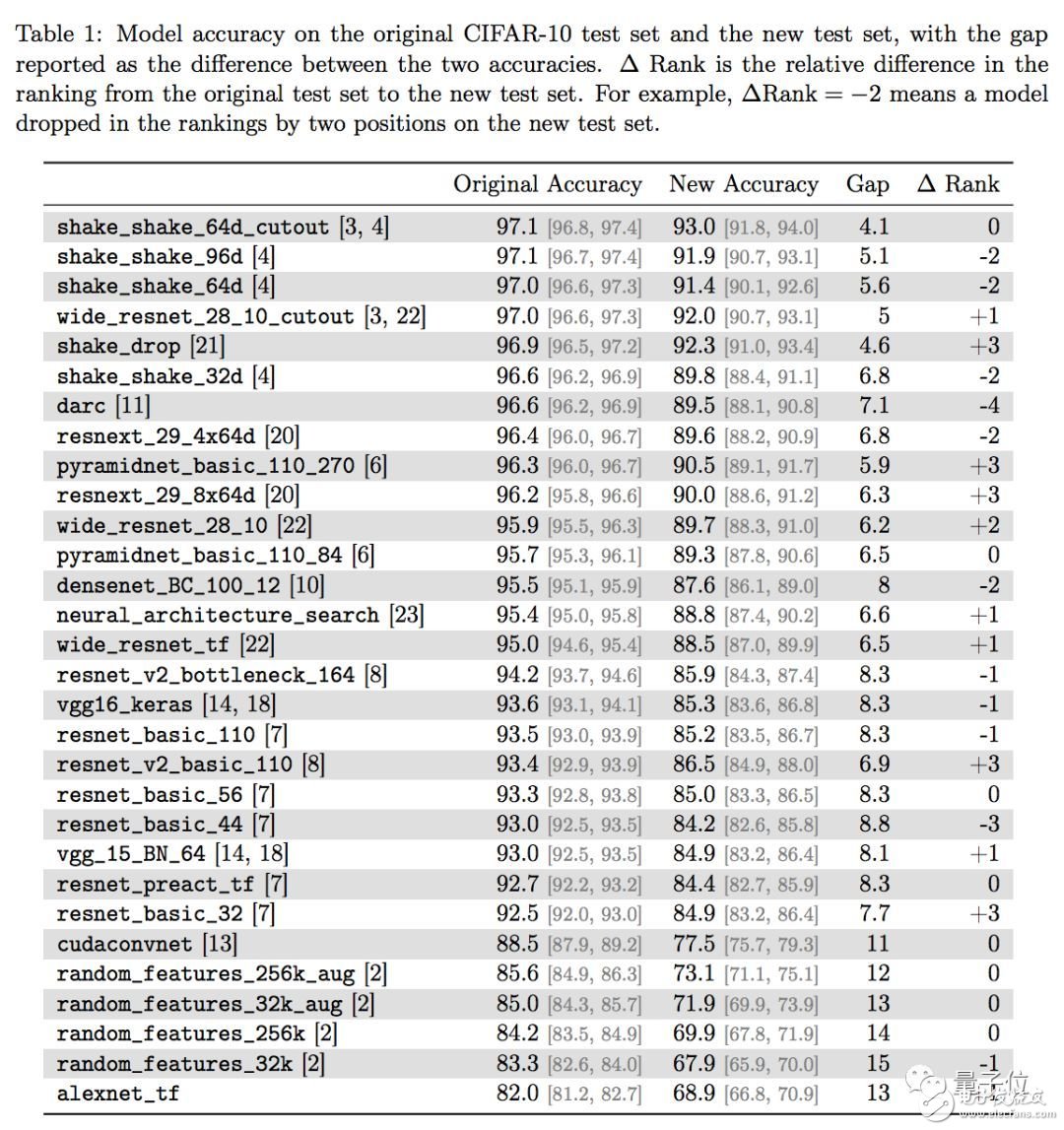
The famous VGG and ResNet, the classification accuracy rate dropped from about 93% to about 85%, and 8 percentage points disappeared out of thin air.
The authors also found a small trend in the difference in accuracy. The new models with higher accuracy on the original CIFAR-10 showed less significant decline in the new test set.
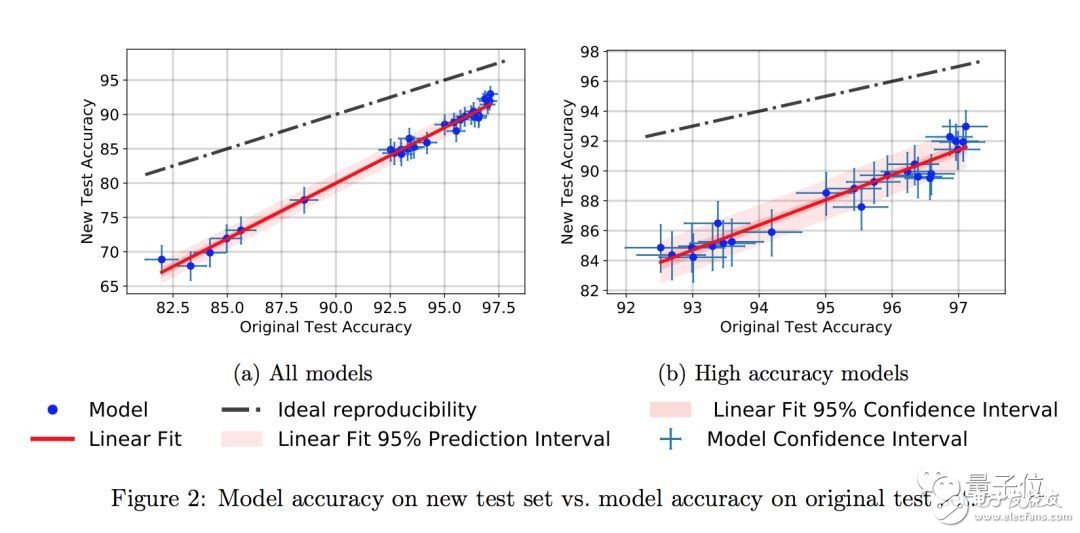
For example, the best-performing Shake Shake model has a accuracy of only 4 percentage points on the old and new test sets.
The paper said that this small trend indicates that the decline in the performance of the data set may not be due to the over-fitting based on adaptability, but because there are some small changes in the distribution of data between the old and new test sets.
But after all, the generalization performance of the classifiers built for CIFAR-10 is still worrying.
Questioning the heat
This study is like a deep water bomb.
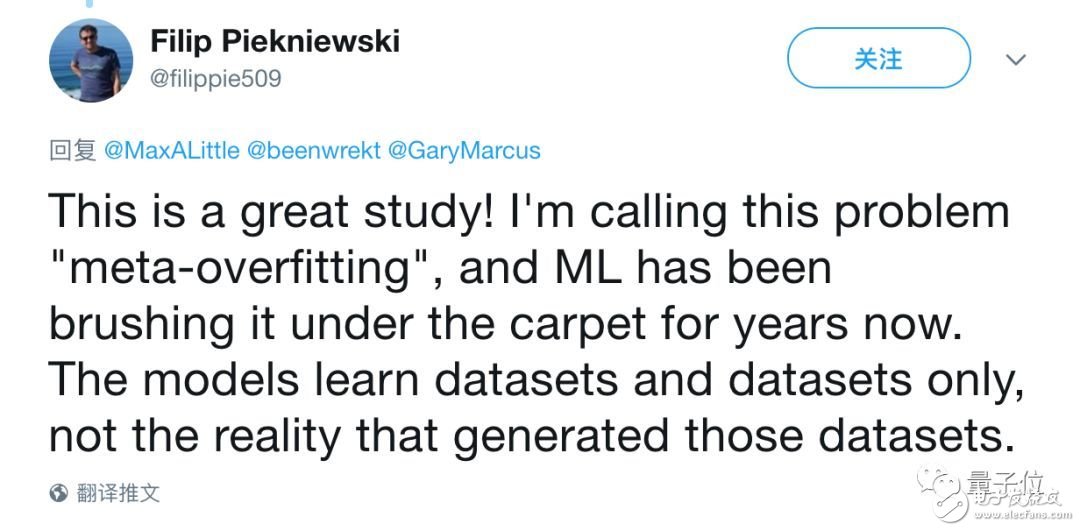
Filip Piekniewski, who wrote an essay on artificial intelligence before, praised the paper as a great study. He also called this problem "meta-overfitTIng". He also criticized machine learning for focusing on only a few data sets in recent years, not paying attention to the reality.
Oregon State University professor Thomas G. Dietterich pointed out that not only CIFAR10, all test data sets were quickly fitted by researchers. Test benchmarks require constant data set injection.
"I have seen a similar situation at MNIST. A classifier with 99% accuracy, for a new handwritten data set, immediately fell to 90%." OpenAI researcher Yaroslav Bulatov said.

Keras author François Chollet is even more excited. He said: "Obviously, a large number of current deep learning tricks have been fitted to well-known benchmarks, including CIFAR 10. At least since 2015, ImageNet has this problem."
If you have a paper, you need a fixed set of validations, as well as specific methods, schemas, and hyperparameters. Then this is not a validation set, but a training set. This particular method does not necessarily generalize to real data.
Research in deep learning often uses unscientific methods. Verification set overfitting is a noteworthy place. Other issues include: the benchmark is too weak, the empirical results do not support the idea of ​​the paper, the reproducibility of most papers, and the selection of results.
For example, when you participate in the Kaggle competition, if you only adjust your model based on the data of the public leaderboard, then your private leaderboard will only perform poorly. This is also true in the broader field of research.
Finally, a very simple suggestion can be made to overcome these problems: using a high-entropy verification process, such as k-fold verification, or even further, using recursive k-fold verification with shuffling. Check the results only on the official verification set at the end.
“Of course, it costs more. But the cost itself is a positive factor: it forces you to act cautiously instead of throwing a large bowl of noodles on the wall to see which one sticks,†says François Chollet.
More than image classification
In fact, this over-fitting problem does not only appear in image classification research, other models are also not immune.
Earlier this year, Microsoft Research Asia and Alibaba's NLP team surpassed humans in the machine reading comprehension dataset SQuAD.
At the time, the organizer of the SQuAD reading comprehension test, the Stanford NLP team had doubts about their data sets. They forwarded a Twitter saying:
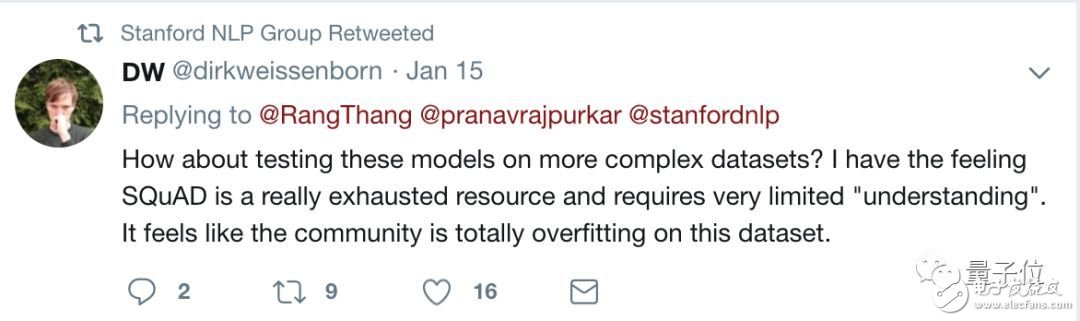
It seems that the entire research community has been fitted on this data set.
Google Brain researcher David Ha also said that he is looking forward to similar research in the field of text and translation. He said that if you see similar results on PTB, it is really good news, maybe a better generalization method will be discovered. .
paper
The authors of this paper include Benjamin Recht from UC Berkeley, Rebecca Roelofs, Vaishaal Shankar, and Ludwig Schmidt from MIT.

The sensor includes linear encoder and rotary encoder, which is used for the position measurement of speed, displacement and angle. Yuheng optics can provide rotary encoders based on optical, magnetic and gear principles, linear encoders based on optical principles and supporting products.

Custom Sensor,Clintegrity Encoder,Absolute Angle Encoder,Small Rotary Encoders
Yuheng Optics Co., Ltd.(Changchun) , https://www.yhenoptics.com