
Editor's note: Sean Owen, director of data science at Databricks, introduced the intuition and interconnections behind common probability distributions.
Data science, no matter what it is, its influence cannot be ignored. "Data scientists are better at statistics than any software engineer." You may accidentally hear an expert say this at a local technical gathering or hackathon. Applied mathematicians have avenged their grievances. After all, people have not talked much about statistics since the roaring twenties. In the past, when chatting, engineers like you would tsk because the analyst had never heard of Apache Bikeshed, a distributed comment formatting project. Now, you suddenly find that people don’t bring you when they talk about confidence intervals. In order to integrate into the chat, in order to become the soul of the party again, you need to make up for statistics. You don’t have to learn the correct understanding, you only need to learn to make people (based on basic observations) think you might understand.
Data Science Venn diagram
Just as data structure is the foundation of computer science, probability distribution is the foundation of statistics. If you plan to chat like a data scientist, then the probability distribution is the starting point for your learning. Sometimes, if you don't understand the probability distribution very much, you can use R or scikit-learn to complete some simple analysis, just like you can write a Java program without understanding the hash function. However, soon you will encounter bugs and false results, and cry out for it, or worse: reap the sighs and blank eyes of statistics professionals.
There are hundreds of probability distributions, and some sound like monsters from medieval legends, such as Muth and Lomax. However, there are only 15 probability distributions that often appear in practice. What are these 15 probability distributions? What wise insights do you need to remember about them? Please see below.
What is a probability distribution?
All kinds of events are happening all the time: dice rolls, raindrops fall, buses arrive at stops. After the incident, the specific result was determined: 3 points plus 4 points were rolled, today’s rainfall is half an inch, and the bus arrives in 3 minutes. Before the incident, we can only discuss the possibility of the outcome. The probability distribution describes our thoughts on the probability of each outcome. Sometimes, we are more concerned with the probability distribution rather than the single most likely outcome. The probability distribution has various shapes, but there is only one size: the sum of the probabilities of the probability distribution is always equal to 1.
For example, tossing a homogeneous coin has two results: heads and tails. (Assuming that it is impossible for a coin to stand on the edge when it falls, or to be stolen by a seagull in the air.) Before tossing a coin, we believe that there is a half chance of throwing it heads, or 0.5 probability. The probability of throwing to the opposite side is the same. This is the probability distribution of the two outcomes of coin tossing. In fact, if you fully understand the above, then you have mastered the Bernoulli distribution.
In addition to strange names, the relationships between common distributions are intuitive and interesting, so it is easy to memorize them or comment on them in an authoritative tone. For example, many distributions can be naturally derived from Bernoulli distributions. It's time to uncover the correlation map of probability distributions.
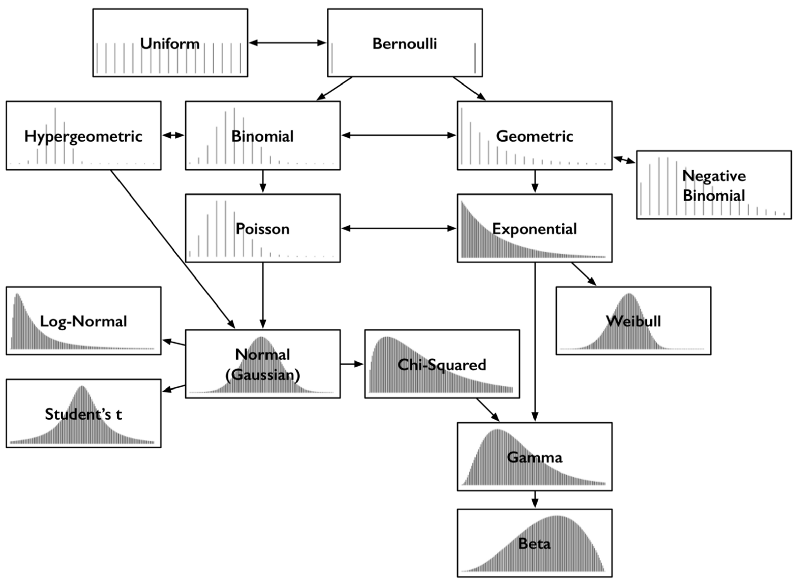
Common probability distributions and their key connections
Each distribution in the figure above contains a corresponding probability mass function or probability density function. This article only deals with the distribution of results as a single number, so the horizontal axis is a collection of possible numerical results. The vertical axis describes the outcome probability. Some distributions are discrete. For example, the result is an integer between 0 and 5, and the probability mass function graph is a sparse straight line. Each line represents a result, and the height of the line represents the probability of the result. Some distributions are continuous, for example, the result is any real number between -1.32 and 0.005, the probability density function is a curve, and the area under the curve represents the probability. The sum of the line heights of the probability mass function and the area under the curve of the probability density function is always equal to 1.
Print out the picture above and put it in your wallet or Kun bag. It can guide you to clarify the relationship between probability distributions and them.
Bernoulli distribution and uniform distribution
You have already touched the Bernoulli distribution through the coin tossing example above. There are two discrete results of coin tossing-heads or tails. However, you can think of the result as 0 (reverse) or 1 (front). The possibility of these two results is the same, as shown in the figure below.

Image source: WolframAlpha
The Bernoulli distribution can represent different possible outcomes, such as tossing an uneven coin. Then, the probability of throwing to the front is not 0.5, but the probability p that is not equal to 0.5, and the probability of throwing to the back is 1-p. Like many distributions, the Bernoulli distribution is actually a series of distributions defined by parameters (The Bernoulli distribution is defined by p). You can think of "Bernoulli" as "tossing (possibly uneven) coins".
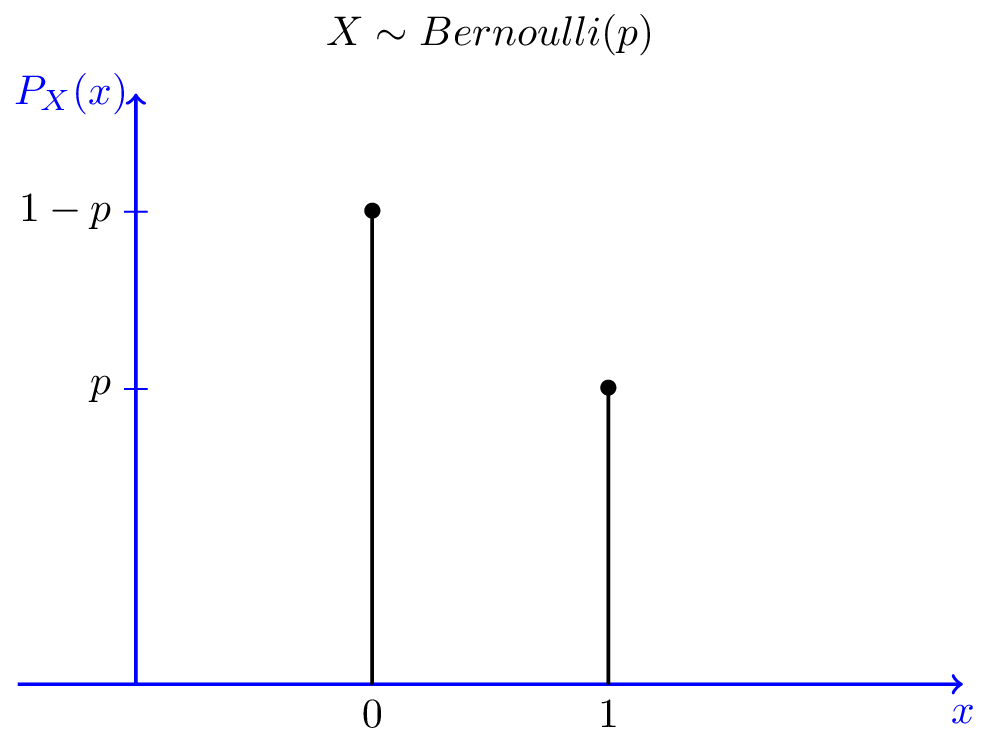
Image source: probabilitycourse.com
There are multiple results, and a distribution with equal probability of all results is a uniform distribution. Imagine tossing a homogeneous dice, the result is 1 to 6 points, and the probability of each point is the same. The uniform distribution can be defined by any number of results n, and it can even be a continuous distribution.

Image source: IkamusumeFan; License: CC BY-SA 3.0
Seeing the even distribution, think of "throwing a homogeneous dice."
Binomial distribution and hypergeometric distribution
The binomial distribution can be regarded as the sum of the results of events following the Bernoulli distribution. Toss a homogeneous coin 20 times. How many times do you throw the heads? The result of this count follows a binomial distribution. Its parameters are the number of trials n and the probability p of "success" ("success" here means heads, or 1). Each toss of a coin obtains a result that follows the Bernoulli distribution, which is a Bernoulli test. When accumulating the number of successes of events similar to coin toss (the result of each coin toss is independent of each other, and the probability of success remains the same), think of the binomial distribution.
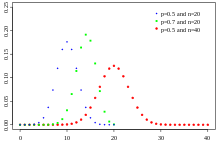
Image source: Tayste (public domain)
Or, you can imagine an urn in which there are equal numbers of white and black balls. Close your eyes, draw a ball from the urn, and record whether it is a black ball, and then put the ball back. Repeat this process. How many times have you drawn a black ball? This count also follows the binomial distribution.
It makes sense to imagine this strange scene, because it makes it easy for us to explain the hypergeometric distribution. In the above scenario, if we don't put back the drawn ball, the result count follows a hypergeometric distribution. There is no doubt that the hypergeometric distribution is the cousin of the binomial distribution, but the two are not the same because the probability of success changes after the ball is removed. If the total number of balls is large relative to the number of draws, then the two distributions are similar, because with each draw, the chance of success changes very little.
When people talk about drawing the ball from the urn without mentioning putting it back, it is almost always safe to insert the sentence "Yes, hypergeometric distribution", because I have never encountered anyone in real life that actually fills the ball with the ball. An urn, then draw the ball from it, and then put it back. (I don't even know who owns an urn.) A broader example is to sample a significant subset of the population.
Poisson distribution
Cumulative number of customers calling the hotline every minute? This sounds like a binomial distribution, if you think of every second as a Bernoulli test. However, the power company knows that during a power outage, hundreds of customers may call in the same second. Treating it as 60,000 millisecond-level trials still cannot solve this problem-the more the number of split trials, the lower the probability of one call, let alone two or more calls, but the probability is lower, Technically speaking, it is not a Bernoulli test. However, if n tends to infinity and p tends to 0, which is equivalent to the infinitely small call probability on infinitely small time slices, we have the limit of the binomial distribution, the Poisson distribution.
Similar to the binomial distribution, the Poisson distribution is the distribution of counts—the counts of occurrence of an event. The parameters of the Poisson distribution are not the probability p and the number of trials n, but the average incidence λ (equivalent to np). When trying to accumulate the occurrence rate of consecutive events and count the number of occurrences of an event in a period of time, don't forget to consider the Poisson distribution.
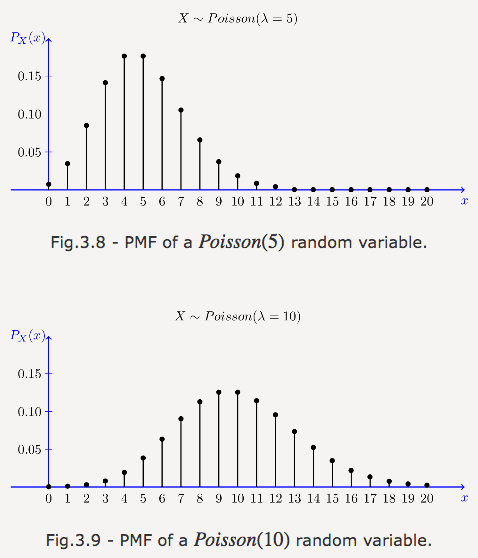
Image source: probabilitycourse.com
Packets arriving at the route, customers visiting the store, things waiting in a certain queue, and things like this, think about "Poisson".
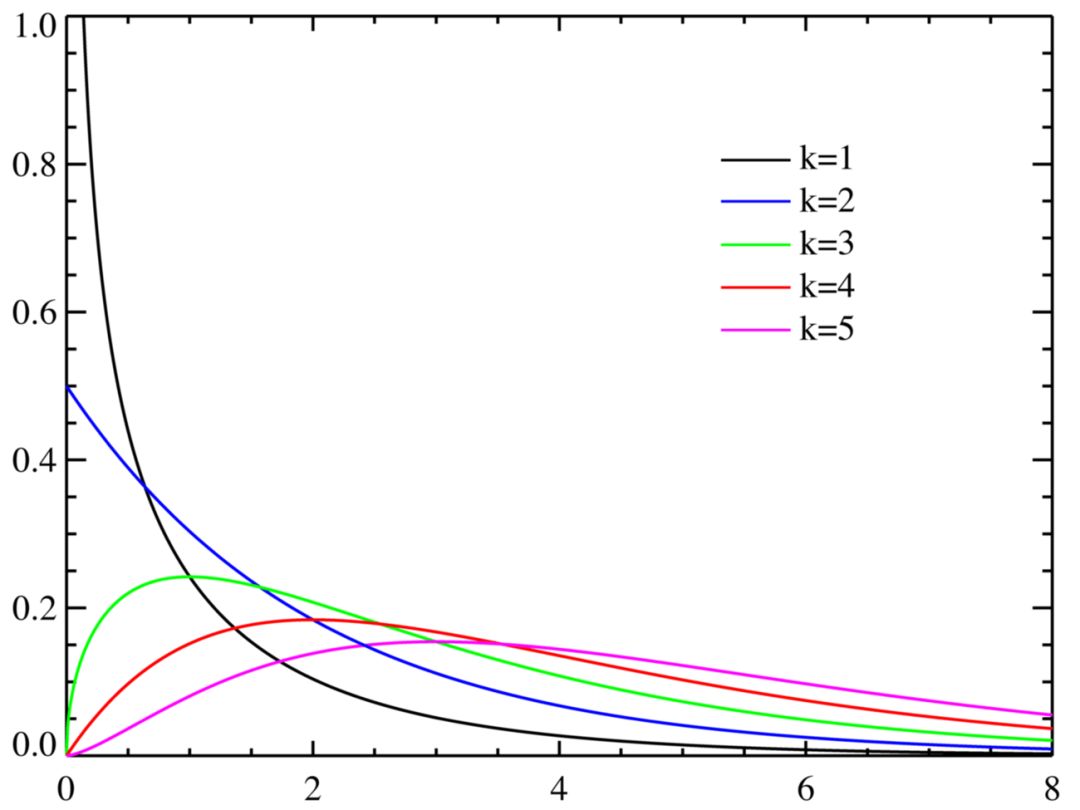
Geometric distribution and negative binomial distribution
Another distribution can be derived from the Bernoulli test. How many times did you throw a coin with the backside up before the first time it appeared upside-down? This count follows a geometric distribution. Similar to the Bernoulli distribution, the geometric distribution is determined by the parameter p (probability of success). The parameter of the geometric distribution does not include the number of trials n, because the result itself is the number of failed trials.

Image source: probabilitycourse.com
If the Bernoulli distribution is "how many times have succeeded", then the geometric distribution is "how many times have failed before succeeding".
The negative binomial distribution is a simple extension of the geometric distribution. It is the number of failures before r successes. Therefore, the negative binomial distribution has an additional parameter, r. Sometimes, the negative binomial distribution refers to the number of successes before r failures. My life mentor told me that success and failure depend on your definition, so these two definitions are equivalent (provided that the probability p is consistent with the definition).
When chatting, if you want to liven up the atmosphere, you can say that, obviously, the binomial distribution and the hypergeometric distribution are a pair, but the geometric distribution and the negative binomial distribution are also very similar, and then ask: "I want to say, who named Is it so messy?"
Exponential distribution and Weibull distribution
Back to the customer support phone example: how long is it until the next customer call? This distribution of waiting time sounds like a geometric distribution, because until the second when there is finally a customer call, every second that no one calls can be regarded as a failure. The number of failures can be regarded as the number of seconds for no one to call, which is almost the waiting time for the next call, but not close enough. The problem this time is that the waiting time calculated in this way is always in whole seconds, and it does not count the waiting time in the second of the customer's final call.
As before, taking the limit to the geometric distribution and moving towards infinitely small time slices can work. We got the exponential distribution. The exponential distribution accurately describes the time distribution before the next call. It is a continuous distribution, because the result is not necessarily a whole second. Similar to the Poisson distribution, the exponential distribution is determined by the parameter occurrence rate λ.

Image source: Skbkekas; License: CC BY 3.0
Echoing the relationship between the binomial distribution and the geometric distribution, the Poisson distribution is "how many times an event has occurred in a given time", and the exponential distribution is "how much time has passed until the event has occurred". Given an event whose number of occurrences in a certain period of time follows a Poisson distribution, then the time interval between events follows an exponential distribution with the same parameter λ. It is based on this correspondence between these two distributions that it is safe to mention the other when talking about one of the two.
When it comes to the "time until an event occurs" (perhaps "time without failure"), exponential distribution should be considered. In fact, trouble-free working time is so important that we have a more general distribution to describe it, the Weibull distribution. The exponential distribution is suitable for cases where the occurrence rate (for example, the probability of damage or failure) is constant, while the Weibull distribution can model the increasing (or decreasing) occurrence rate over time. The exponential distribution is just a special case of the Weibull distribution.
When chatting turns to trouble-free working hours, consider "Weibull".
Normal distribution, lognormal distribution, t distribution, chi-square distribution
The normal distribution, also known as the Gaussian distribution, is perhaps the most important probability distribution. Its bell-shaped curve is very recognizable. Like the natural logarithm e, the magical normal distribution can be seen everywhere. A large number of samples from the same distribution-any distribution-and then added together, the sum of the samples follows the (approximate) normal distribution. The larger the number of samples, the more the sum of the samples approximates to a normal distribution. (Warning: It must be a non-pathological distribution, it must be an independent distribution, and only tends to a normal distribution). This is true regardless of the original distribution, which is really surprising.
This is called the Central Limit Theorem. You must know the term and its meaning, or you will be laughed at.

Image source: mfviz.com
In this sense, the normal distribution is related to all distributions. However, normal distribution and accumulation are particularly relevant. The sum of Bernoulli experiment follows the binomial distribution. As the number of trials increases, the binomial distribution becomes closer and closer to the normal distribution. The hypergeometric distribution of its cousins ​​is the same. The Poisson distribution-the extreme form of the binomial distribution-also approaches the normal distribution as the incidence parameter increases.
If you take the logarithm of the result and the result follows a normal distribution, then we say that the result follows a lognormal distribution. In other words, the logarithm of the normal distribution value follows the lognormal distribution. If the sum follows a normal distribution, then the corresponding product follows a lognormal distribution.
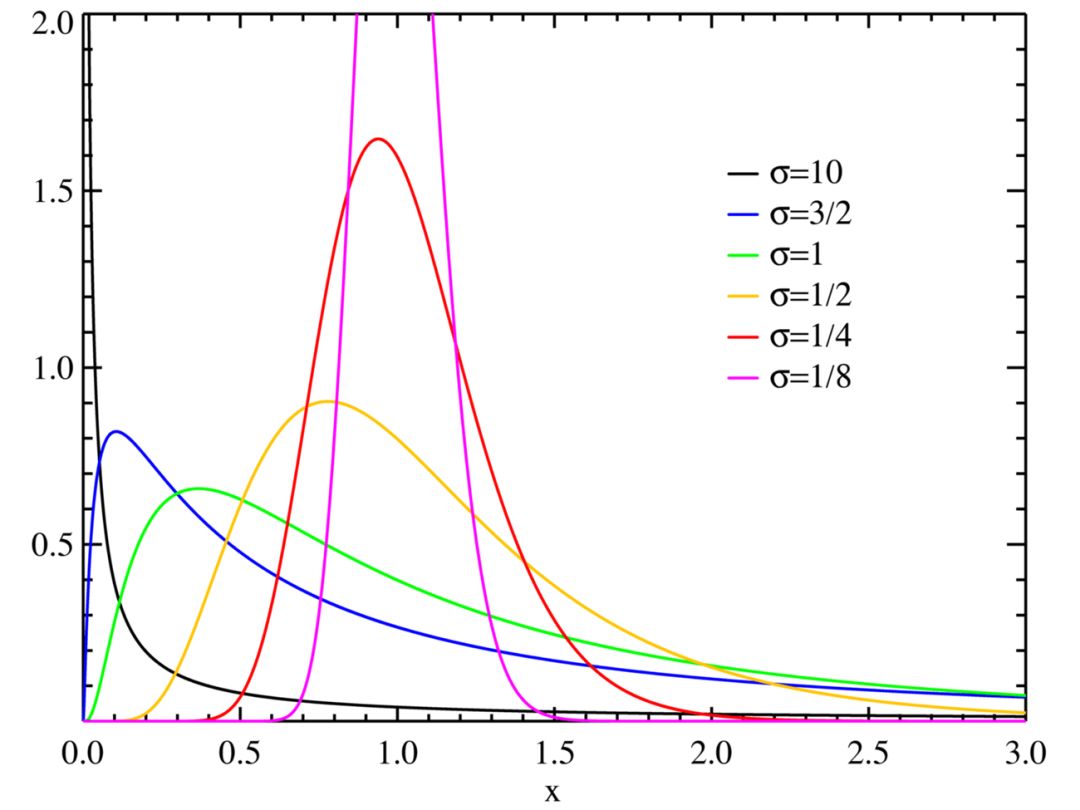
Image source: Wikipedia
Student t-distribution is the basis of t-test, and many non-statisticians have been exposed to t-test in other disciplines. It is used to infer the mean value of the normal distribution, and as its parameters increase, it gets closer to the normal distribution. The main feature of the student t-distribution is that the tail is thicker than the normal distribution (see the figure below, the red line is the student t-distribution, and the blue line is the standard normal distribution).

Image source: IkamusumeFan; License: CC BY-SA 3.0
If the thick-tailed argument does not arouse the neighbor’s surprise, then you can tell a more interesting background story related to beer. A hundred years ago, Guinness used statistics to brew better stout beer. In Guinness, William Sealy Gosset developed a new statistical theory to grow better barley. Gosset convinced the boss that other brewers could not figure out how to use these ideas and obtained permission to publish the results, but published under the pseudonym "student". Gosset's most famous result is the student t-distribution, which is named after him to some extent.
Finally, the chi-square distribution is the distribution of the sum of squares of the values ​​of the normal distribution. It is the basis of the chi-square test. The chi-square test is based on the sum of the squares of the difference between the observed value and the theoretical value (assuming the difference follows a normal distribution).
Gamma distribution and beta distribution
If it's all about chi-square distribution, then the conversation should be considered serious. You may be chatting with a real statistician. For this reason, you may apologize, saying that you don’t know much, because nouns such as gamma distribution will appear. The gamma distribution is a generalization of the exponential distribution and the chi-square distribution. The gamma distribution is often used as a complex model of waiting time, which is more like an exponential distribution. For example, the gamma distribution can be used to model the time before the next n-th event occurs. In machine learning, the gamma distribution is a "conjugate prior" of some distributions.
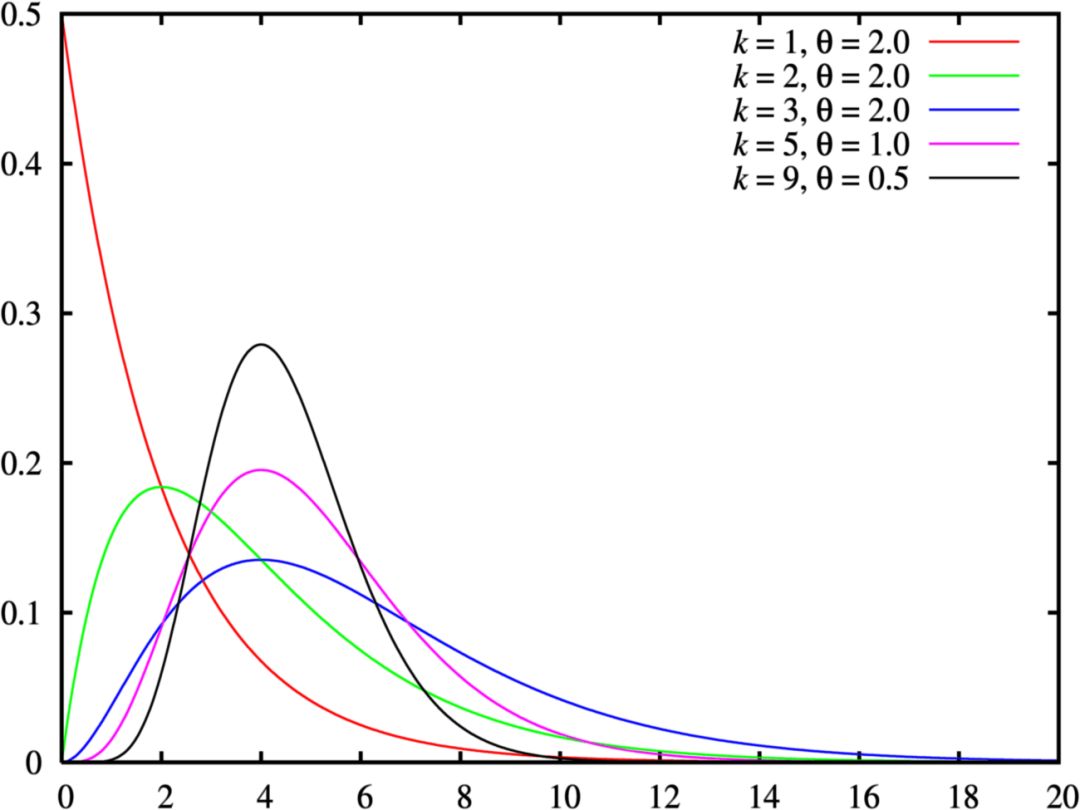
Image source: Wikipedia; License: GPL
Don't interject in the conversation about conjugate priors, but if you do, be prepared to talk about the beta distribution, because it is the conjugate prior of most of the distributions mentioned above. As far as data scientists are concerned, the use of beta distribution is mainly here. Mention this inadvertently, and then move towards the door.
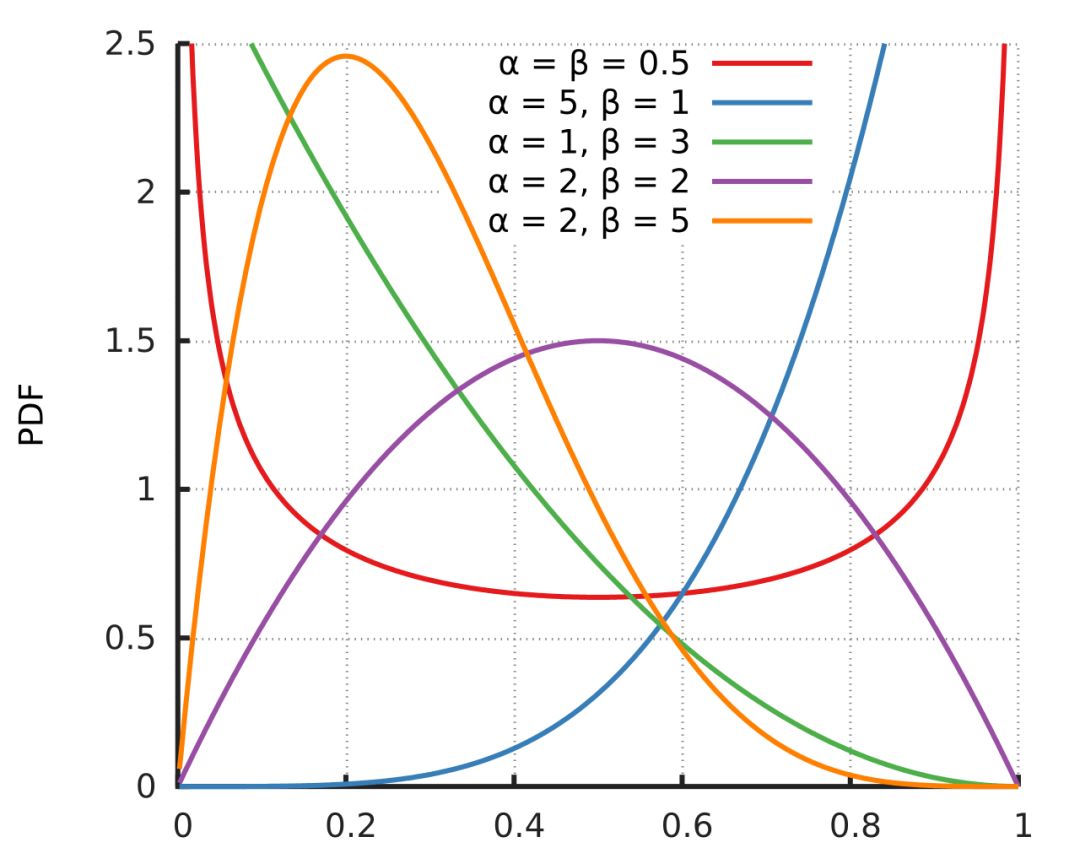
Image Credit: Horas; License: Public Domain
The beginning of wisdom
The knowledge of probability distribution is vast. Those who are really interested in the probability distribution can start with the following map of the distribution of all units.
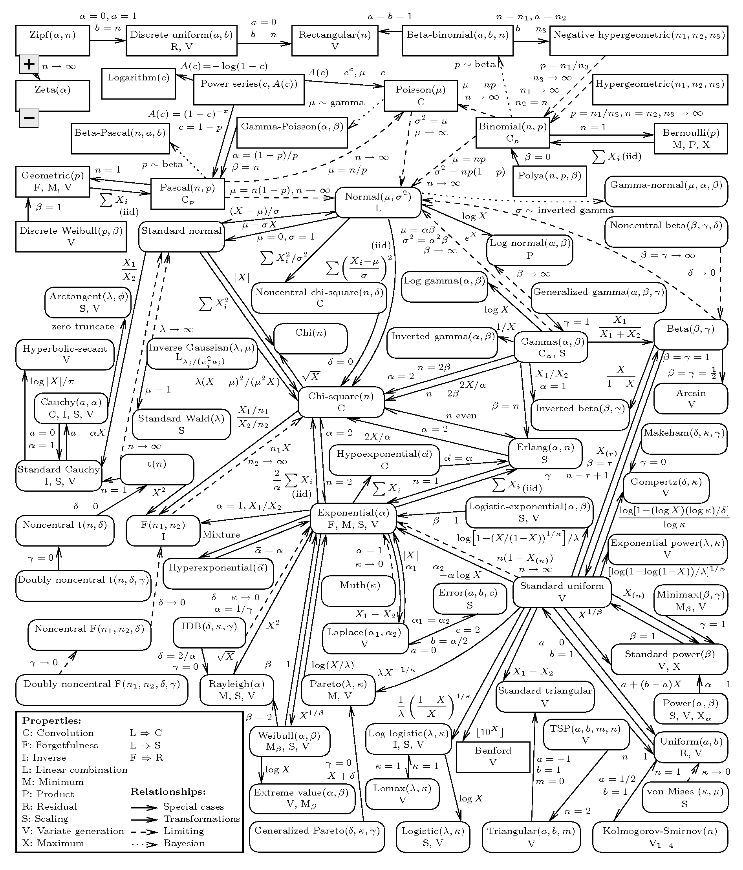
I hope this article will give you a little confidence and make yourself look knowledgeable and able to integrate into today's technological culture. Or, at least it can provide you with a way to judge with a high probability when you should find a cocktail party that is not so dumb.
Comcn Electronics Limited , https://www.comencnspeaker.com