
Model pruning is considered to be an effective model compression method. However, is the pruning method really as effective as claimed in the literature? The paper "Rethinking Pruning" recently submitted to ICLR 2019 by researchers from UC Berkeley and Tsinghua University questioned six pruning methods, which caused concern.
Network pruning is one of the commonly used model compression methods, which is widely used to reduce the heavy calculation of deep models.
A typical pruning algorithm usually has three stages, namely training (large model), pruning and fine-tuning. In the pruning process, according to certain standards, the redundant weights are pruned and the important weights are retained to maximize the accuracy.
Pruning usually greatly reduces the number of parameters, compresses the space, and reduces the amount of calculation.

However, are pruning methods really as effective as they claim?
A recent paper submitted to ICLR 2019 seems to contradict the results of all recent network pruning-related papers. This paper questioned the results of several commonly used model pruning methods, including Song Han, who was awarded the ICLR2016 best paper. "Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding".
This paper quickly attracted attention, and some people believed that it might even change our workflow for training and deploying models in industry. The authors of the paper are from UC Berkeley and Tsinghua University. They have some interesting feedback on OpenReview with the author of the model they questioned. Interested readers can check it out. address:
https://openreview.net/forum?id=rJlnB3C5Ym

Paper address:
https://arxiv.org/pdf/1810.05270.pdf
In this paper, the author found several observations that contradict common beliefs. They checked the 6 most advanced pruning algorithms and found that fine-tuning the pruned model is only slightly better or worse than the performance of the network trained with random initialization weights.
The author said: “For pruning algorithms that use a predefined target network architecture, you can get rid of the entire pipeline and train the target network directly from scratch. Our observations are that for various pruning algorithms with multiple network architectures, data sets, and tasks Consistent."
The author concludes that this finding has several implications:
1) Training a large, over-parameterized model is not necessary to obtain an efficient small model;
2) In order to obtain the small model after pruning, it is not necessarily useful to obtain the "important" weights of the large model;
3) The pruned structure itself, rather than a set of "important" weights, is the reason for the improved effect of the final model. This shows that some pruning algorithms can be regarded as performing a "network architecture search".
Overthrow the two common beliefs behind network pruning
Over-parameterization is a common attribute of deep neural networks, which leads to high computational cost and high memory usage. As a remedy, network pruning has been proven to be an effective improvement technique that can improve the efficiency of deep networks with limited computational budgets.
The process of network pruning generally includes three stages: 1) training a large, over-parameterized model, 2) pruning the trained large model according to specific standards, and 3) fine-tune the pruned model to Regain lost performance.

The three stages of network pruning
Usually, there are two common beliefs behind this pruning procedure.
First of all, people think it is important to start with training a large, over-parameterized network, because it provides a high-performance model from which a set of redundant parameters can be safely removed without significantly compromising accuracy. Therefore, this is generally considered to be a better method than training a smaller network directly from scratch, and it is also a commonly used baseline method.
Secondly, the pruned structure and its related weights are considered necessary to obtain the final effective model.
Therefore, most of the existing pruning techniques choose the fine-tune pruning model instead of training from scratch. The weights retained after pruning are generally considered to be critical, so how to accurately select important weight sets is a very active research topic.
In this work, we found that the two beliefs mentioned above are not necessarily correct.
Based on the empirical evaluation of the latest pruning algorithm on multiple data sets with multiple network architectures, we have drawn two surprising observations.

Figure 2: The difference between predefined and non-predefined target architectures
First, for a pruning algorithm with a predefined target network architecture (Figure 2), directly training a small target model from random initialization can achieve the same (or even better) performance as the model obtained by the pruning method. In this case, you do not need to start with a large model, but you can directly train the target model from scratch.
Secondly, for pruning algorithms without a predefined target network, training the pruning model from scratch can also achieve performance equivalent to or even better than fine-tune. This observation shows that for these pruning algorithms, what is important is the obtained model architecture, not the retained weights, although finding the target structure requires training a large model.
Our results advocate rethinking the existing network pruning algorithm. It seems that over-parameterization during the first phase of training is not as beneficial as previously thought. In addition, inheriting weights from a large model is not necessarily optimal, and may trap the pruned model into a bad local minimum, even if the weights are deemed "important" by the pruning criteria.
On the contrary, our results show that the value of automatic pruning algorithms lies in identifying effective structures and performing implicit architecture search, rather than choosing “important†weights. We verified this hypothesis through carefully designed experiments and showed that the patterns in the pruning model can provide design guidance for effective model architecture.
How to train a small model from scratch
This section describes how to train a small target model from scratch.
Target Pruned Architectures
We first divide the network pruning methods into two categories. In the pruning pipeline, the architecture of the target pruning model can be determined by humans (pre-defined) or pruning algorithms (automatic) (see Figure 2).
Data set, network architecture and pruning method
In the related literature of network pruning, CIFAR-10, CIFAR-100 and ImageNet datasets are de facto benchmarks, while VGG, ResNet and DenseNet are common network architectures.
We evaluated three pruning methods for predefined target architectures: Li et al. (2017), Luo et al. (2017), He et al. (2017b), and evaluated three pruning methods for automatically discovering target models Methods Liu et al. (2017), Huang & Wang (2018), Han et al. (2015).
Training budget
A key question is, how long should we spend training this pruned small model from scratch? It may be unfair to train with the same number of epochs as training a large model, because a small model requires much less computation in an epoch.
In our experiments, we use Scratch-E to represent the small pruning model for training the same epoch, and Scratch-B to represent the same amount of computational budget for training.
Implementation (Implementation)
In order to make our settings as close to the original paper as possible, we used the following protocol:
1) If the training settings of the previous pruning method are public, such as Liu et al. (2017) and Huang & Wang (2018), use the original implementation;
2) For simpler pruning methods, such as Li et al. (2017) and Han et al. (2015), we re-implemented the pruning method and obtained similar results to the original paper;
3) In the other two methods (Luo et al., 2017; He et al., 2017b), the pruned model is public, but there is no training setting, so we choose to train the target model from scratch.
The results and the code for training the model can be found here:
https://github.com/Eric-mingjie/rethinking-networks-pruning
Experiments and results
In this section, we will show experimental results that compare training pruning models from scratch and fine-tuning methods based on inherited weights, as well as pre-defined and automatically discovered target architectures. It also includes transfer learning experiments from image classification to object detection.

Table 1: Results (accuracy) of channel pruning based on L1 norm. The "pruning model" is a model for pruning from a large model. The configurations of the original model and the pruning model are from the original paper.
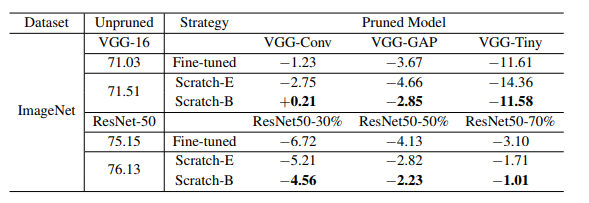
Table 2: Results (accuracy) of ThiNet. "VGG-GAP" and "ResNet50-30%" refer to the pruning model configured in ThiNet. In order to adapt to the influence of the different frameworks between the method in this paper and the original paper, we compared the relative accuracy drop with respect to the large-scale model without pruning. For example, for the pruned model VGG-Conv is -1.23, which means that the accuracy of 71.03 on the left has decreased, which is the reported accuracy of the unpruned large VGG-16 in the original paper
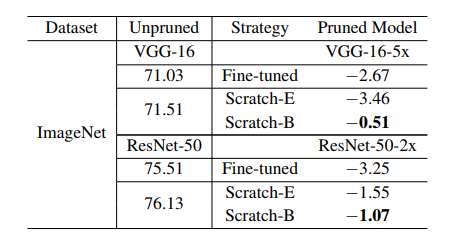
Table 3: Regression-based feature reconstruction results (accuracy). Similar to Table 2, we compare the relative accuracy drop compared to the large model without pruning.
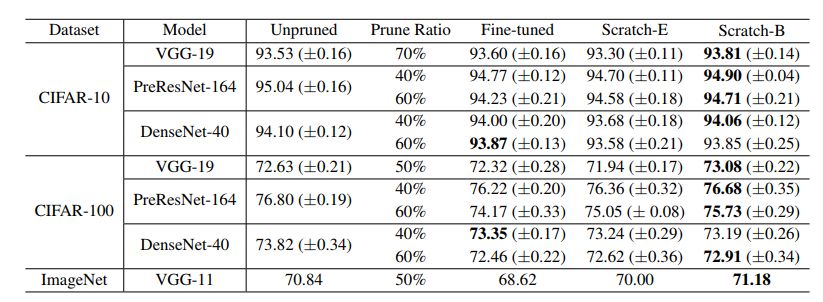
Table 4: Network Slimming results (accuracy) "Pruning ratio" indicates the total percentage of pruning channels in the entire network. Each model uses the same ratio as the original paper.

Table 5: Pruning results (accuracy) of residual blocks selected using sparse structure. There is no need for fine-tuning in the original paper, so there is a "pruned" column instead of a "fine-tuned" column
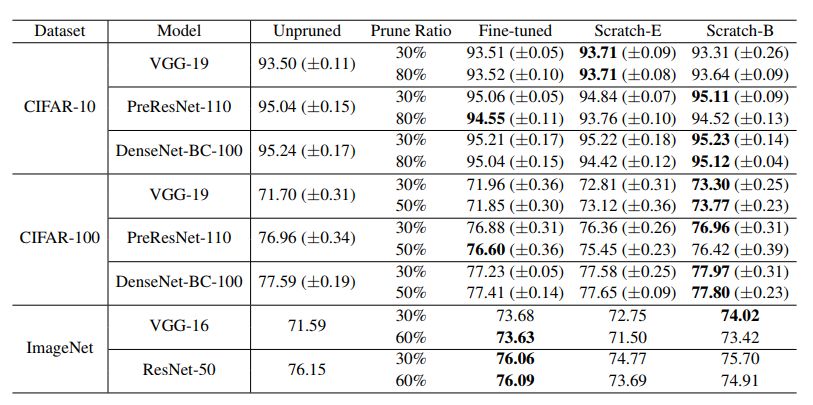
Table 6: Results (accuracy) of unstructured pruning The "pruning ratio" indicates the ratio of the parameters for pruning in all convolution weight sets.

Table 7: Pruning results (mAP) used for detection tasks. Prune-C refers to the weight of the pre-training of pruning classification, and Prune-D refers to the pruning after the weight is transferred to the detection task. Scratch-E/B means to train the classification pruning model from scratch and move to the detection task.
In short, for a pruning method for a predefined target architecture, using the same number of iterations as the large model (Scratch-E) to train a small model is usually sufficient to achieve the same accuracy as the three-step output model. In addition, the target architecture is predefined. In practical applications, people are often more willing to train small models directly from scratch.
In addition, if you have a computational budget (computing power) equivalent to that of a large model, the performance of the model trained from scratch may even be higher in fine-tuning the model.
Discussion and conclusion
We suggest that in the future, relatively high-performance baseline methods should be used to evaluate pruning methods, especially for architecture pruning with predefined targets. In addition to high accuracy, training a predefined target model from scratch has the following advantages over traditional network pruning:
• Because the model is smaller, you can use fewer GPU resources to train the model, and it may be faster than training the original large model.
• There is no need to implement pruning standards and procedures. These procedures sometimes need to be fine-tuned layer by layer and/or need to be customized for different network architectures.
• It is possible to avoid adjusting other hyperparameters involved in the pruning process.
Our results can use pruning methods to find efficient architectures or sparse patterns, which can be accomplished by automatic pruning methods. In addition, in some cases, traditional pruning methods are much faster than training from scratch, such as:
•Pre-trained large models have been provided, and the training budget is small.
• It is necessary to obtain multiple models of different sizes. In this case, a large model can be trained and then pruned at different scales.
In summary, our experiments show that training a small pruning model from scratch can almost always achieve an accuracy equal to or higher than that obtained by a typical "training-pruning-fine-tuning" process. This changes our understanding of the necessity of over-parameterization, and further proves the value of automatic pruning algorithms, which can be used to find efficient architectures and provide guidance for architecture design.
Jiangmen Hongli Energy Co.ltd , https://www.honglienergy.com