
I believe that your friends must have studied the two best papers of CVPR this year. One is from Stanford and Berkeley University researchers on how to carry out efficient transfer learning: Taskonomy: Disentangling Task Transfer Learning, another A paper from Carnegie Mellon University: Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies achieves 3D reconstruction and tracking of multi-scale human behavior. But in addition to this, four outstanding works were awarded honorary nominations for best papers, respectively from:
Imperial College Dyson Robotics Lab: CodeSLAM — Learning a Compact, Optimisable Representation for Dense Visual SLAM;
University of California Merced, University of Massachusetts Amherst and Nvidia: SPLATNet: Sparse Lattice Networks for Point Cloud Processing;
Lund University, Romanian Academy of Sciences: Deep Learning of Graph Matching;
The Austrian Institute of Science and Technology, the Max Planck-Tubingen Institute, the Heidebara International Institute of Information Technology and the University of Cambridge: four papers on Efficient Optimization for Rank-based Loss Functions, respectively, from geometric description, point cloud processing, and graphics Research on matching and optimization, let's learn together!
CodeSLAM — Learning a Compact, Optimisable Representation for Dense Visual SLAM
In the real-time three-dimensional perception system, the expression of object geometry has always been a very critical issue, especially in the positioning and mapping algorithm, which not only affects the geometric quality of the mapping, but also is closely related to the algorithm it adopts. In SLAM, especially monocular SLAM, scene geometry information cannot be obtained from a single perspective, and the inherent uncertainty becomes difficult to control under large degrees of freedom. This makes the current mainstream slam divided into two directions: sparse and dense. Although dense maps can capture geometric surface topography and be enhanced with semantic tags, the huge storage calculations brought by its high-dimensional characteristics limit its application, and it is not suitable for precise probability estimation. Sparse features can avoid these problems, but capturing features of some scenes is only useful for localization problems.
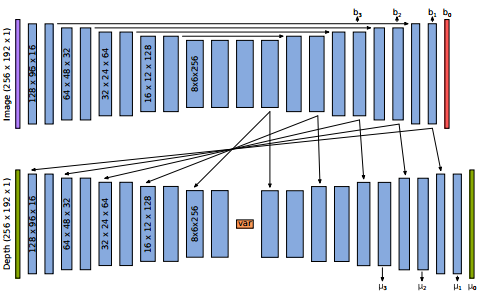
In order to solve these problems, the author in this article proposes a compact but dense geometric representation of the scene, which is based on a single intensity map of the scene and is generated by encoding with few parameters. The researchers designed this method inspired by the work of image learning depth and self-encoder. This method is suitable for dense slam systems based on key frames: each key frame can generate a depth map through encoding, and the encoding can be optimized through pose variables and overlapping key frames to maintain global continuity. The trained depth map can enable the coded representation of local geometric features that cannot be predicted directly from the image.
The contribution of this article is mainly in two aspects:
Derive a dense set representation of the deep autoencoder trained by intensity map, and optimize it;
For the first time, a monocular system with joint optimization of dense sets and motion estimation was realized.
The following figure is the network architecture adopted by the researchers, which implements a variational depth autoencoder based on image intensity.
The following figure shows the different outputs of the codec stage and the ability of the code to capture details:

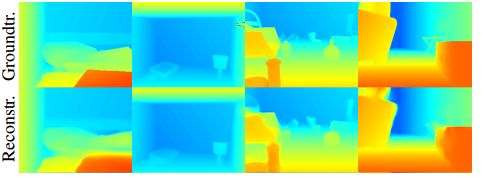
The following figure is the recovery after encoding and the sfm result:

The researchers hope to build a complete real-time SLAM system based on key frames in the future, and devote themselves to studying a more compact representation of general 3D geometry in the future, and even use it for 3D object recognition.
If you are interested, you can visit the project homepage for more detailed information, or see the attached video introduction:
http: //
SPLATNet: Sparse Lattice Networks for Point Cloud Processing
The data of three-dimensional sensors such as lidar are often in the form of irregular point clouds. Analyzing and processing point cloud data plays a very important role in robots and autonomous driving.
However, the point cloud has the characteristics of sparseness and disorder, which makes it very difficult for the general convolutional neural network to process 3D point data, so at present, the point cloud is mainly processed by manual features. One method is to preprocess the point cloud to conform to the input form of standard spatial convolution. According to this idea, the deep learning architecture for 3D point cloud analysis requires preprocessing of irregular point clouds, or voxel representation, or projection to 2D. This requires a lot of manpower and will lose the natural invariance information contained in the point cloud.
In order to solve these problems, in this article, the author proposes a network architecture for processing point clouds, the key of which is that the research finds that bilateral convolution layers (e bilateral convolution layers (BCLs) have many advantages for processing point clouds Characteristics.
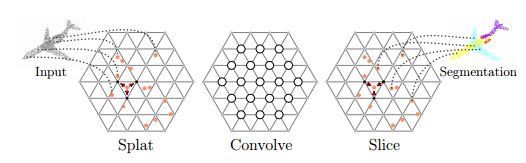
Bilateral convolution layer
BCLs provide a systematic method to remove out-of-order points, but at the same time maintain the flexibility of the grid in convolution operations. BCL smoothly maps the input point cloud to a sparse grid, and performs a convolution operation on the sparse grid, then performs smooth interpolation and maps the signal to the original input. Using BCLs, researchers have established SPLATNet (SParse LATtice Networks) for layered processing of unordered point clouds and recognition of spatial features.
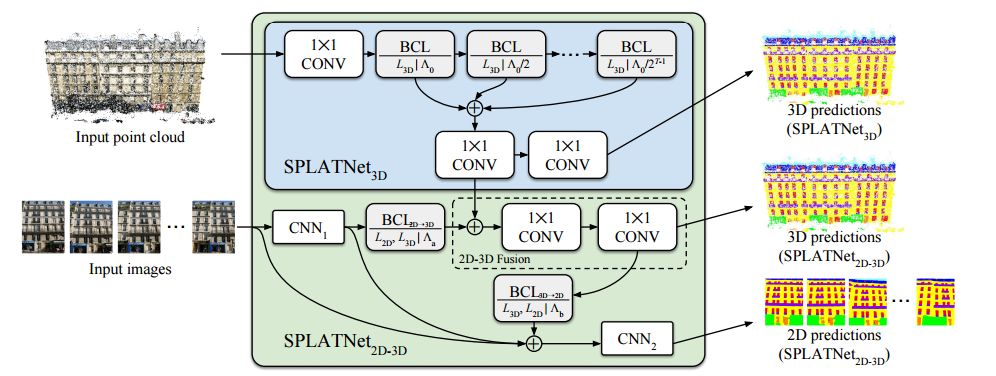
SPLATNet architecture
It has the following advantages:
No need for point cloud preprocessing;
Can facilitate the implementation of neighborhood operations like standard CNN;
Using hash tables can efficiently process sparse input;
Use sparse and efficient grid filtering to realize the processing of input point cloud layering and spatial features;
Can realize mutual mapping between 2D-3D.

2D to 3D projection
The following figure is the processing result of the building point cloud:

If you are interested, you can refer to the project homepage:
http: // vis-
And Nvidia's official introduction: https://news.developer.nvidia.com/nvidia-splatnet-research-paper-wins-a-major-cvpr-2018-award/
If you want to get started, there is code to run a wave: https://github.com/NVlabs/splatnet
Today ’s attachment contains a video introduction, so stay tuned.
https://pan.baidu.com/s/1dIyZyEx-Bc9zYPIr4F_5bw
Deep Learning of Graph Matching
The problem of graph matching is an important problem in optimization, machine learning, and computer vision, and how to represent the relationship between a node and its adjacent structure is the key. This article proposes an end-to-end model to make it possible to learn all the parameters in the graph matching process. It includes unit and pair of node neighborhoods, which is expressed as deep layered feature extraction.
The calculation process of the complete training graph matching model
The difficulty lies in establishing a complete process starting from the loss function for matrix operations between different layers and achieving efficient and continuous gradient propagation. The matching problem is solved by combining optimization layers, and hierarchical feature extraction is used. Finally, good results were obtained in the computer vision experiment.

It can be seen that the graph matching algorithm for key points still performs well in each instance where the shape and pose are very different.
Efficient Optimization for Rank-based Loss Functions
In information retrieval systems, complex loss functions (AP, NDCG) are usually used to measure the performance of the system. Although the parameters of the retrieval system can be estimated by positive and negative samples, these loss functions are not differentiable or decomposable, making gradient-based algorithms unusable. Usually people circumvent this problem by optimizing the upper boundary of the loss-hing function or using an asymptotic method.

System algorithm
To solve this problem, researchers have proposed an algorithm for large-scale non-differentiable loss functions. Provides a description of the loss function in accordance with this algorithm, which can handle loss functions including AP and NDCC series. At the same time, the researchers also proposed a non-comparative algorithm to improve the computational complexity of the above progressive process. This method has better results than the simpler decomposable (requires training) loss function.
Widely Used Nail Staples,Upholstery Fences Staple,Factory Special Application Staple,Cages Hog Rings Nail
Zhejiang Best Nail Industrial Co., Ltd. , https://www.beststaple.com